|
查看: 591|回复: 27
|
不用ChatGPT了!歐洲靠DeepSeek挑戰美國
 [复制链接]
[复制链接]
|
|
|
本帖最后由 dalap 于 4-2-2025 09:26 AM 编辑
2025年1月27日
(广东27日讯)中国AI新创企业DeepSeek(深度求索)近期推出“DeepSeek-V3”与“DeepSeek-R1”两款最新的AI模型。这两款模型具备低廉的制造成本,且采用运算能力相对低阶的英伟达H800晶片,却拥有与全球顶尖AI语言模型匹敌的表现(例如OpenAI 的 ChatGPT-4),让矽谷巨头相当震惊。
《观点财经》报导,据美国匿名职场论坛TeamBlind上,一位自称Meta员工的贴文,自DeepSeek发布DeepSeek-V3以来,Meta旗下的Llama 4在各项测试中落后,让公司的生成式AI部门陷入恐慌。
更令人忧虑的是,这间鲜为人知的中国公司仅耗资557万美元(约2437万令吉)就达成这项技术成就。
该Meta员工指出,公司内部生成式AI部门的高阶主管薪资都超过DeepSeek的开发成本,而Meta目前拥有数十位此类高管,令人质疑部门庞大成本的合理性。
Meta试图复制技术
该员工透露,目前Meta工程师正疯狂研究分析DeepSeek的成功秘诀,试图复制任何可复制的技术。然而,当DeepSeek-R1发布时,情况变得更加严峻。该员工表示,虽然无法透露具体细节,但一些资讯将很快公开。
DeepSeek-V3于去年12月26日发布后,随即成为开源模型的领头羊。DeepSeek公布的技术报告数据显示,Meta的Llama 3.1-405B仅在 MMLU-Pro大规模多任务理解数据集上接近DeepSeek-V3的水平,而在其他项目中表现几乎都不及八成。
今年1月20日,DeepSeek正式发表DeepSeek-R1,官方技术报告中的对照模型,仅包含OpenAI公司的闭源模型OpenAI o1以及自家模型DeepSeek-v3。
在前次DeepSeek-V3测试中被拿来做对照的Meta、Anthropic等公司模型在本次报告中已销声匿迹。 |
|
|
|
|
|
|
|
|
|
|
|
 发表于 2-2-2025 11:36 AM
|
显示全部楼层
发表于 2-2-2025 11:36 AM
|
显示全部楼层
公开开源也许已经是过去式的技术,
更好的技术可能已经在路上,
这个就是比赛竞跑。有能力就跟的上,没有能力就抄书好了。
等你消化了,下一个作业又来了。 |
评分
-
查看全部评分
|
|
|
|
|
|
|
|
|
|
|
发表于 2-2-2025 12:14 PM
|
显示全部楼层
一个星期前还震惊无比,现在是惊喜连连.gif) |
|
|
|
|
|
|
|
|
|
|
|
发表于 2-2-2025 12:47 PM
来自手机
|
显示全部楼层
|
Deepseek开发者梁文峰的家乡已经成为网红热门的打卡地点了。 |
|
|
|
|
|
|
|
|
|
|
|
发表于 2-2-2025 12:51 PM
|
显示全部楼层
本帖最后由 lcw9988 于 2-2-2025 12:57 PM 编辑
更好的技术可能已经在路上? 幻想以后会怎样, 嘴炮谁不会 !
我只讲发生的事实, 最新gpt-o3 mini又公佈了, 这个案例证明o3 mini 吊打deepseek ! 吊打deepseek ! 吊打deepseek ! , oh yeah !
https://www.reddit.com/r/OpenAI/ ... _race_a_sidebyside/
DeepSeek R1 和 OpenAI o3-mini 的并排比较
我们将针对一个复杂的推理任务对这两个模型进行并排比较:生成一个复杂、语法有效的 SQL 查询。
我们将根据以下标准比较这些模型:
准确度:模型是否生成了正确的响应?
延迟:模型生成响应需要多长时间?
成本:大致而言,哪个模型生成响应的成本更高?
前两个类别非常不言自明。下面我们将比较成本。
我们知道 DeepSeek R1 的成本为每百万个输入令牌 0.75 美元,每百万个输出令牌 2.4 美元。
图片:OpenRouter 的 R1 成本
相比之下,OpenAI 的 o3 的成本为每百万个输入令牌 1.10 美元,每百万个输出令牌 4.4 美元。
图片:OpenAI 的 O3-mini 成本
因此,o3-mini 的每次请求成本大约高出 2 倍。
但是,如果模型生成不准确的查询,则应用程序层内有自动重试逻辑。
因此,为了计算成本,我们将查看模型重试的次数,计算发送的请求数,并创建估计成本指标。R1 的基准成本为 c,因此无需重试,因为 o3-mini 的成本为 2c(因为它的成本是其两倍)。
现在,让我们开始吧!
使用 LLM 生成复杂、语法有效的 SQL 查询
我们将使用 LLM 生成语法有效的 SQL 查询。
此任务对于现实世界的 LLM 应用程序非常有用。通过将简单的英语转换为数据库查询,我们将界面从按钮和鼠标点击更改为我们都能理解的东西——语言。
它的工作原理是:
我们接受用户的请求并将其转换为数据库查询
我们对数据库执行查询
我们接受用户的请求、模型的响应和查询的结果,并要求 LLM 对响应进行“评分”
如果“评分”高于某个阈值,我们会向用户显示答案。否则,我们会抛出错误并自动重试。
A) 让我们从 R1 开始。
对于这项任务,我将从 R1 开始。我会要求 R1 向我展示强劲的股息股票。以下是请求:
向我展示具有以下特征的大盘股:
股息收益率 >3%
5 年股息增长率 >5%
债务/股权 <0.5
我要求模型分别执行两次此操作。在两次测试中,模型要么超时,要么没有找到任何股票。
图片:从 R1 生成的查询
仅从手动检查来看,我们可以看出:
它使用总负债(而非债务)作为比率
它试图查询全年收益,而不是使用最新季度
它使用平均股息收益率作为过去 12 个月的股息数字
最后,我不得不直接检查数据库日志以查看经过的时间。
图片:数据库中聊天记录的屏幕截图
这些日志显示模型在 41 分钟后最终放弃!这太疯狂了!显然不适合实时财务分析。
因此,对于 R1,最终得分为:
准确率:未生成正确响应 = 0
成本:重试 5 次,成本为 5c + 1c = 6c
延迟:41 分钟
R1 的表现不太好……
B) 现在,让我们使用 OpenAI 的新 O3-mini 模型重复此测试。
接下来是 O3, 我们将向 O3-mini 提出完全相同的问题。
与 R1 不同,速度的差异是天壤之别。
我在下午 6:26 提出问题,并在 2 分 24 秒后收到回复。
图片:从开始到结束日志中的时间戳
这包括 1 次重试尝试、一次评估查询的请求和一次汇总结果的请求。
最后,我得到了以下回复。
图片:来自模型的响应
我们得到了符合我们查询的股票列表。康菲石油、芝加哥商品交易所集团、EOG Resources 和 DiamondBack Energy 等股票的股息大幅增长,负债权益比非常低,市值也很高。
如果我们点击消息底部的“信息”图标,我们还可以检查查询。
图片:O3-mini 生成的查询
通过人工检查,我们知道此查询符合我们的要求。因此,对于我们的最终成绩:
准确度:它生成了正确的响应 = 1
成本:1 次重试尝试 + 1 次评估查询 + 1 次汇总查询 = 3c * 2(因为它的成本是 r1 的两倍)= 6c
延迟:2 分 24 秒
对于这个例子,我们可以看到 o3-mini 在各方面都比 r1 更好。它的速度快了几个数量级,成本相同,并且它为复杂的财务分析问题生成了准确的查询。
能够以低于去年日常使用模型的价格完成所有这些工作绝对令人难以置信。
总结性想法
DeepSeek 发布 R1 后,我承认我给了 OpenAI 很多批评。从极其昂贵的价格到完全搞砸的 Operator,再到发布一个缓慢、无法使用的伪装成 AI 代理的玩具,OpenAI 在 1 月份遭受了很多失败。他们用 O3-mini 弥补了所有这些。这个模型让他们重新回到了 AI 竞赛中,并获得了惊人的第一名
R1 用了41分钟, 一共重复6次, 成本6c, 做不出要的东西.
o3 mini 用了2.5分钟, 一共重复3次, 成本6c, 做出要的东西.
o3 mini 吊打 R1 !, o3 Pro也快公布了 ! 
@开卷有益
|
评分
-
查看全部评分
|
|
|
|
|
|
|
|
|
|
|
发表于 2-2-2025 01:02 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 2-2-2025 01:29 PM
|
显示全部楼层
本帖最后由 开卷有益 于 2-2-2025 11:19 PM 编辑
我一开始就已经发表了我对现时期的ai的看法,认为这只不过是ai的开始,就好像是一个人刚刚上小学。ai的强大不是人们可以想象的到的,用的好,就是人类突破下一个文明的奇点,用不好就是人类文明的终点。
我再一次强调之前那个chat训练模式是对的,只有把好的,坏的,没用的,有用的灌进去,才可能给ai产生意识,ai一天不产生意识,始终是个冷冰冰的机械罢了,这就是人类试图创神的一个计划罢了。如果以现在地球资源分配,硬件技术来无限提供给这个ai学习,这是不可能做到的,这就是为什么ic要不停的做到最小,是因为小的ic不需要这么多能源,科学家也在不停的试图寻找新计算机模式,譬如量子电脑,零界限导体,再生能源等等。。
deep的出现是打破了以往的训练方式,它认为只要人为的把需要训练的东西打包喂给ai学习,在某个方向短时间必然会有很突出的效果,也已经做到了这一点。但是我们真的需要这训练出来的效果吗?答案也是肯定需要的,这个阶段的ai,可以在某某特定方向学习的比人类快,也可以很有效的给与解决方案,但是这些方案还需要人类这个老师来确定最后可不可用。
deep的出现,开了另外一个造神之路,如果说chat的神是一神论,那么deep就是多神论。就好像我们现在的学习系统一样,每个人都去学习不同的东西,然后一起开会,最好互相分享自己学到的东西,一起解决问题。
chat的一神论是没有问题的,而且很简单,缺点就是没有先进技术和现有资源无法做到ai最终体。
deep的多神论在这个阶段也是看不到问题的,问题是最后如何把这么多个神合为一体,达到ai最终体。
chat面对的是科技和资源问题。seed将来要面对的也是科技和资源问题。
只不过chat所面对的问题是已经可以预见的,seed将要面对的问题是不可预见的。
我一开始就表达了我对seed出现的看法,我认为seed是个搅局者,可以是正面的,带动ai研究,发展的积极性,也可以是负面的,把已有的训练模式分为两个训练模式,同样的资源已经很难供应给其中一个了,现在是两个,以后将会有更多个。 |
评分
-
查看全部评分
|
|
|
|
|
|
|
|
|
|
|
发表于 2-2-2025 02:28 PM
|
显示全部楼层
本帖最后由 祈s 于 2-2-2025 02:31 PM 编辑
openai是个成年人的年代至少已经在这个ai领域许久。。
如果炸了几千亿还输的话是可以理解。对我们是没有什么影响,不过对OpenAI的投资人来说就大条咯,看他们还会凸钱千亿,我想是在南摩做梦竹篮打水一场空。
deepseek现在是普天盖地的到处开花结果,实行小打胜过垄断的OpenAI。
时间是关键,OpenAI剩下的时间券钱自救,千亿自俞,百亿的话还吊点滴。
我以为deepseek是在赶杀。日久自有功,害怕的是OpenAI。
白宫正在走衰败之运,如果拉其进局只有败局。
|
|
|
|
|
|
|
|
|
|
|
|
发表于 2-2-2025 02:56 PM
|
显示全部楼层
白宫正在走衰败之运? 不是你说的2023吗? 你还这么大的勇气? 要改几次哦? 2099 ? 你能见证吗?
Claude 3.5 的训练成本大约是几千万( a few $10 Millions),如下面的链接所示!
https://darioamodei.com/on-deepseek-and-export-controls
成本曲线下降的历史趋势是每年约 4 倍,这意味着在正常业务过程中——在历史成本下降的正常趋势中,例如 2023 年和 2024 年发生的情况——我们预计现在的模型比 3.5 Sonnet/GPT-4o 便宜 3-4 倍。由于 DeepSeek-V3 比美国前沿模型更差——假设在扩展曲线上差约 2 倍,我认为这对 DeepSeek-V3 来说相当慷慨——这意味着如果 DeepSeek-V3 的训练成本比一年前开发的当前美国模型低约 8 倍,这将是完全正常的,完全“符合趋势”。我不会给出一个数字,但从前面的要点可以清楚地看出,即使你从表面上看 DeepSeek 的训练成本,它们充其量也符合趋势,甚至可能甚至不符合趋势。例如,这比原来的 GPT-4 和 Claude 3.5 Sonnet 推理价格差异(10 倍)要小,而且 3.5 Sonnet 是一个比 GPT-4 更好的模型。所有这些都表明,DeepSeek-V3 并不是一项独特的突破,也不是从根本上改变 LLM 经济的东西;它是持续成本降低曲线上的一个预期点。这次的不同之处在于,第一个展示预期成本降低的公司是中国公司。
假设 Claude 3.5 的1次训练成本是 5000 万(2023 年训练),1 年后减少 4-8 倍,成本是 50/6 = 850 万,而 deepseek 的1次成本是 600 万(2024 年训练)!
所以差别不大,不是媒体所说的 3%。
|
|
|
|
|
|
|
|
|
|
|
|
发表于 2-2-2025 05:23 PM
|
显示全部楼层
仅仅在 DeepSeek 之后几天,另一家中国 AI 公司 Moonshot 发布了 Kimi k1.5 模型,超越了 OpenAI
梅胡尔·鲁宾·达斯 • 2025年1月29日,13:28:49 IST
Whatsapp
Twitter
Moonshot 的 Kimi k1.5 是一个多模态 AI 模型,集成了视觉、文本和代码输入来解决复杂问题。在一些基准测试中,它在问题解决和推理等领域超过了 OpenAI 的一些模型,提升幅度高达 550%。
Moonshot 的 Kimi k1.5 是一个多模态 AI 模型,能够处理文本和图像,这使其在需要两种格式的任务中具有优势。与 DeepSeek 的 DeepSeek-R1 不同,后者没有多模态功能,Kimi 能够在文本和图像之间进行推理和处理。令 Kimi 特别令人印象深刻的是,它的开发成本仅为美国类似前沿 AI 模型的一个小部分。图片来源:Kimi
AI 技术竞赛迎来了新的一章,中国的 Moonshot AI 在 DeepSeek 的 DeepSeek-R1 崛起几天后,推出了其最新的模型 Kimi k1.5。尽管 DeepSeek 已被视为 OpenAI GPT-4 的强大竞争对手,Kimi k1.5 现在被誉为一个更强大的替代品,在一些关键基准测试上超越了 OpenAI 的 GPT-4o 和 Claude 3.5 Sonnet。
这一举动标志着中国在 AI 领域日益增长的影响力,挑战着美国科技巨头的主导地位。
Kimi k1.5 是什么?
Kimi k1.5 由北京的初创公司 Moonshot AI 开发,是一个多模态 AI 模型,集成了视觉、文本和代码输入来解决复杂问题。它被誉为 OpenAI 的 GPT-4o 的直接竞争对手,一些报告甚至表示它在数学、编程以及理解文本和视觉数据等领域超越了 GPT-4。与没有多模态能力的 DeepSeek-R1 不同,Kimi 可以处理并推理文本和图像,使其在需要这两种格式的任务中占据优势。Kimi 之所以特别令人印象深刻,是因为它的开发成本仅为美国类似前沿 AI 模型的一个小部分。据报道,Kimi k1.5 被誉为 OpenAI 模型的第一个真正竞争者。
Kimi 的独特功能
Kimi k1.5 不仅仅是另一个 AI 模型,它代表了强化学习(RL)和多模态推理的重大突破。该模型使用强化学习技术通过探索奖励来增强决策过程。这使得 Kimi 能够将复杂问题分解成可管理的步骤,从而提高其推理能力。Kimi 被设计用于处理长上下文任务,能够处理多达 128,000 个标记,这使它能够基于大量数据理解和生成回应。其将视觉数据、文本和代码结合的能力使其高度多功能,非常适合广泛的应用。
在基准测试方面,Kimi 在多个领域超越了 GPT-4o 和 Claude 3.5 Sonnet。它在 MATH 500 测试中得分 96.2,超过了 GPT-4 的各个版本,并在 AIME 数学基准测试中得分 77.5。它在 Codeforces 竞争性编程平台的得分也进入了 94 百分位。该模型在某些基准测试中的表现比美国的同类模型高出多达 550%,特别是在问题解决和推理领域。然而,这些分数的可靠性常常受到质疑,因为 AI 公司通常会自行进行基准测试并发布结果。
Kimi 的影响
Kimi k1.5 的效率和多功能性使其与许多现有的 AI 模型区分开来,其推出引起了 AI 社区的广泛关注。随着它在推理、数学和长上下文任务等领域持续超越领先的美国模型,Kimi 可能会在医疗、工程和数据分析等依赖 AI 的行业中掀起革命。尽管关于基准测试可靠性的质疑存在,但 Kimi 在技术进步上的影响是不可否认的。
凭借其多模态能力和强化学习方法,Kimi k1.5 预计将在塑造 AI 未来中发挥重要作用。随着中国在 AI 竞赛中进一步巩固其地位,Kimi 的崛起无疑向美国科技公司发出了一个明确的信号——他们必须加速创新,才能跟上这一迅速发展的领域。
https://www.firstpost.com/tech/j ... penai-13857457.html
|
评分
-
查看全部评分
|
|
|
|
|
|
|
|
|
|
|
发表于 2-2-2025 07:45 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 2-2-2025 10:24 PM
|
显示全部楼层
本帖最后由 开卷有益 于 2-2-2025 10:28 PM 编辑
可以免费使用是好事来的,对于普通用户来讲也可以体验一些chat的高级功能。
|
|
|
|
|
|
|
|
|
|
|
|
发表于 2-2-2025 11:45 PM
来自手机
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 3-2-2025 12:53 AM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|

楼主 |
发表于 4-2-2025 09:25 AM
|
显示全部楼层
不用ChatGPT了!歐洲靠DeepSeek挑戰美國 吐殘忍真相
大陸新創公司DeepSeek推出低成本高效率的AI開源模型震撼全球,被看好改寫人工智慧產業的趨勢,歐洲科技公司則將DeepSeek視為迎頭趕上的機會,冀望拉近與美國科技巨頭的差距。
路透社報導,德國新創公司Novo AI的負責人Hemanth Mandapati是DeepSeek模型的早期使用者,早在兩周前就從OpenAI的ChatGPT轉向,Hemanth Mandapati說:「DeepSeek的報價比實際價格低5倍,我們省下很多錢,但客戶卻沒看到任何差異。」
丹麥新創公司Empatik AI執行長Ulrik RT也說:「我認為DeepSeek對我們這樣的公司是一個巨大的機會,不需要鉅額預算就能實現願景。」研究機構Bernstein分析師預估,DeepSeek模型的價格比OpenAI同類模型便宜20至40倍。
過往,歐洲科技公司很難與更容易獲得資金的美國科技巨頭競爭,無法在第一時間採用新技術,但DeepSeek的出現讓科技業高層認為,遊戲規則可能會被改變。
目前歐洲只有法國的Mistral能夠與OpenAI、Meta、Anthropic和Google主導的最先進人工智慧模型競爭,美國創投業對人工智慧公司的投資高達1000億美元,但歐洲創投業對人工智慧公司的投資僅158億美元,兩者差距明顯。 |
|
|
|
|
|
|
|
|
|
|
|
发表于 4-2-2025 12:50 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 6-2-2025 12:02 AM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 6-2-2025 01:56 PM
|
显示全部楼层
美国新法案:下载DeepSeek 监20年 罚1亿!
time
3小时前
view
9299点阅
责任编辑: 国际小编
(华盛顿6日综合电)美国国会近日提出了一项名为《2025年美国人工智能能力与中国脱钩法案》的新法案,核心是禁止美国人在中国境内推进AI能力,中美在AI领域彻底脱钩。
美国参议员乔什·霍利近日提出了一项激进的法案,要求美国对中国AI技术进行严格限制,甚至把下载和使用中国AI模型(如DeepSeek)定为非法行为——相关违法者将面临最高20年监禁及最高1亿美元的罚款。
霍利在声明中明确表示,DeepSeek的发布是他提出该法案的直接原因。
法案指出,任何下载或使用DeepSeek的行为将被定性为犯罪,最高可判处20年监禁。另外,如果与中国的高校、大学或实验室合作,可能涉及违法行为,并对违反规定的行为设定了民事罚款,具体为个人罚款100万美元(约441.53万令吉),公司罚款1亿(约4.42亿令吉)美元,此外赔偿金额为3倍。
该法案的另一重要条款是将其视为加重罪行,特别是在移民法框架下,意味着任何涉及技术转移的非美国公民,将可能面临被驱逐出境的风险。值得注意的是,早在法案提出之前,美国总统就已开始屏蔽DeepSeek,包括国防部、国会和NASA等部门。
https://www.chinapress.com.my/?p=4291944 |
|
|
|
|
|
|
|
|
|
|
|
发表于 6-2-2025 04:14 PM
来自手机
|
显示全部楼层
题外话, 中国特警在阿联酋举办的世界特警大赛里获得冠军与季军!
掌声鼓励鼓励。。。👏👏👏👏👏👏👍 |
|
|
|
|
|
|
|
|
|
|
|
发表于 6-2-2025 05:14 PM
|
显示全部楼层
这条水,粉丝6百万,现在几乎发一个视频要过3百万都难了。。
|
|
|
|
|
|
|
|
|
|
| |
 本周最热论坛帖子 本周最热论坛帖子
|









 变色卡
变色卡 千斤顶
千斤顶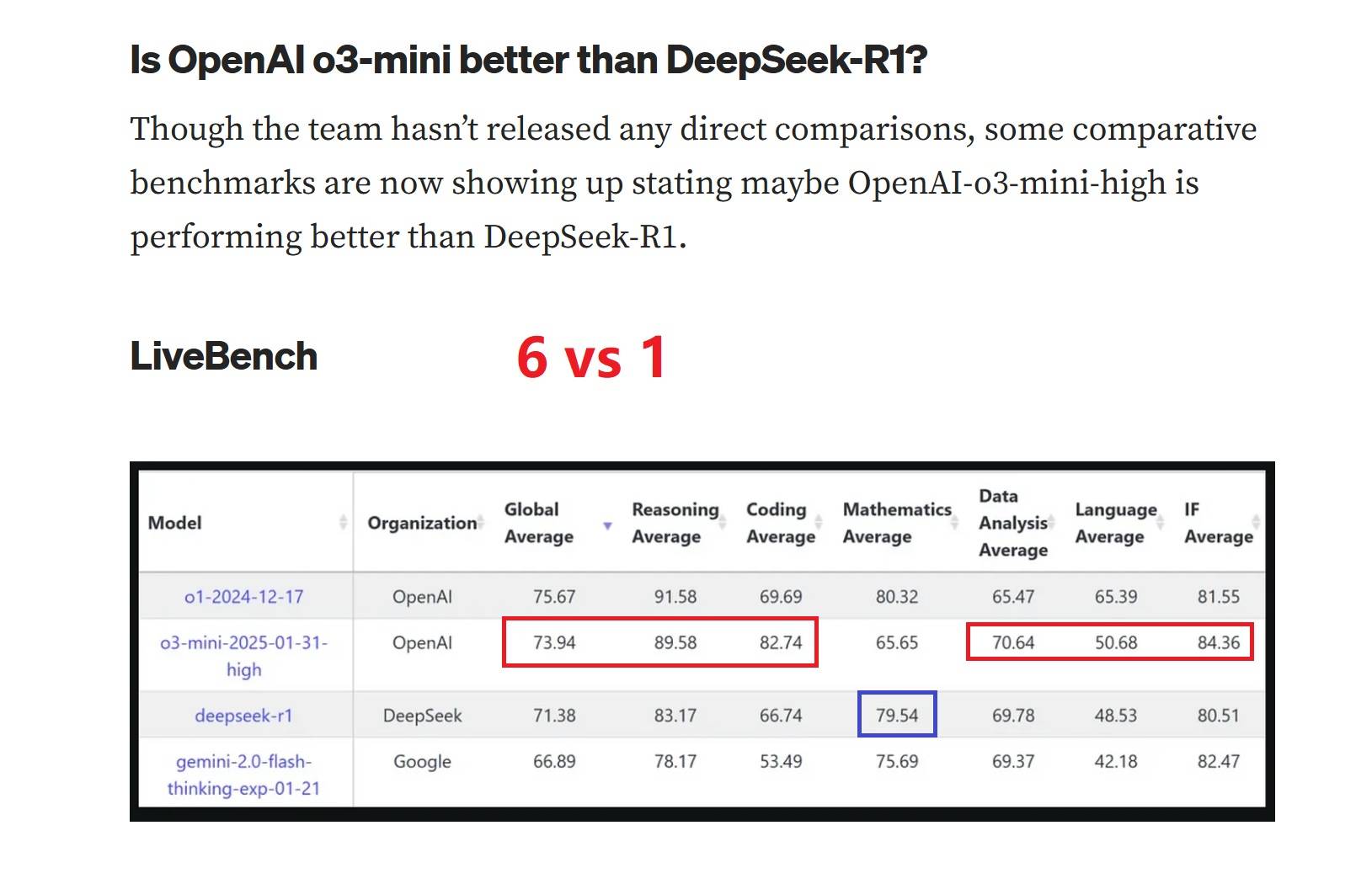

 1898
1898  47
47